
End of training
Browse files- README.md +2 -1
- all_results.json +13 -0
- eval_results.json +8 -0
- runs/Aug01_14-28-05_ip-10-192-10-179/events.out.tfevents.1722522664.ip-10-192-10-179.23427.1 +3 -0
- train_results.json +8 -0
- trainer_state.json +130 -0
- training_eval_accuracy.png +0 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -6,6 +6,7 @@ metrics:
|
|
| 6 |
- accuracy
|
| 7 |
tags:
|
| 8 |
- llama-factory
|
|
|
|
| 9 |
- generated_from_trainer
|
| 10 |
model-index:
|
| 11 |
- name: llama2_7b_test_4
|
|
@@ -17,7 +18,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 17 |
|
| 18 |
# llama2_7b_test_4
|
| 19 |
|
| 20 |
-
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
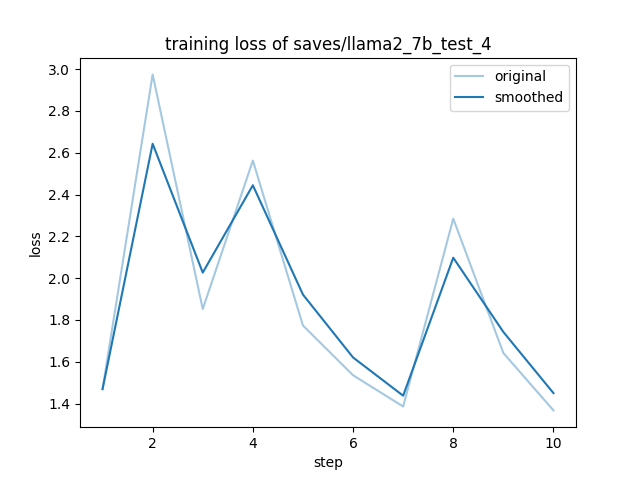
- Loss: 1.6859
|
| 23 |
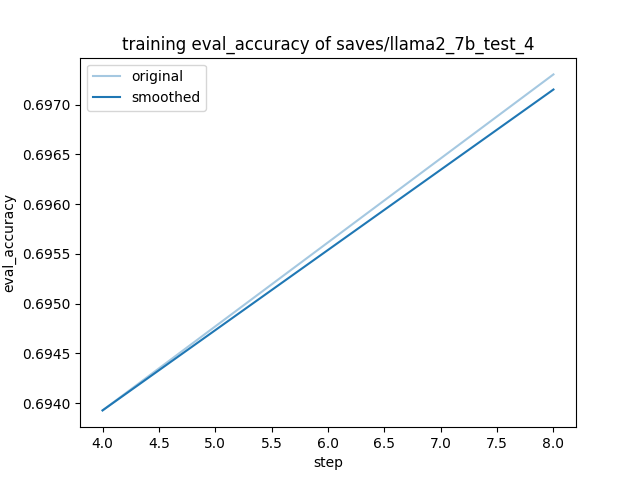
- Accuracy: 0.6973
|
|
|
|
| 6 |
- accuracy
|
| 7 |
tags:
|
| 8 |
- llama-factory
|
| 9 |
+
- lora
|
| 10 |
- generated_from_trainer
|
| 11 |
model-index:
|
| 12 |
- name: llama2_7b_test_4
|
|
|
|
| 18 |
|
| 19 |
# llama2_7b_test_4
|
| 20 |
|
| 21 |
+
This model is a fine-tuned version of [meta-llama/Llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf) on the alpaca_en_demo dataset.
|
| 22 |
It achieves the following results on the evaluation set:
|
| 23 |
- Loss: 1.6859
|
| 24 |
- Accuracy: 0.6973
|
all_results.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 0.08888888888888889,
|
| 3 |
+
"eval_accuracy": 0.6973038730142216,
|
| 4 |
+
"eval_loss": 1.685868740081787,
|
| 5 |
+
"eval_runtime": 21.0785,
|
| 6 |
+
"eval_samples_per_second": 4.744,
|
| 7 |
+
"eval_steps_per_second": 4.744,
|
| 8 |
+
"total_flos": 591688209530880.0,
|
| 9 |
+
"train_loss": 1.8846651792526246,
|
| 10 |
+
"train_runtime": 97.4531,
|
| 11 |
+
"train_samples_per_second": 0.821,
|
| 12 |
+
"train_steps_per_second": 0.103
|
| 13 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 0.08888888888888889,
|
| 3 |
+
"eval_accuracy": 0.6973038730142216,
|
| 4 |
+
"eval_loss": 1.685868740081787,
|
| 5 |
+
"eval_runtime": 21.0785,
|
| 6 |
+
"eval_samples_per_second": 4.744,
|
| 7 |
+
"eval_steps_per_second": 4.744
|
| 8 |
+
}
|
runs/Aug01_14-28-05_ip-10-192-10-179/events.out.tfevents.1722522664.ip-10-192-10-179.23427.1
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3d76346f1091b8a822cf24489f696d89d53bb1e4a13ecf7d52deedd2ed3fff55
|
| 3 |
+
size 405
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 0.08888888888888889,
|
| 3 |
+
"total_flos": 591688209530880.0,
|
| 4 |
+
"train_loss": 1.8846651792526246,
|
| 5 |
+
"train_runtime": 97.4531,
|
| 6 |
+
"train_samples_per_second": 0.821,
|
| 7 |
+
"train_steps_per_second": 0.103
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": 1.685868740081787,
|
| 3 |
+
"best_model_checkpoint": "saves/llama2_7b_test_4/checkpoint-8",
|
| 4 |
+
"epoch": 0.08888888888888889,
|
| 5 |
+
"eval_steps": 4,
|
| 6 |
+
"global_step": 10,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.008888888888888889,
|
| 13 |
+
"grad_norm": 0.9656311869621277,
|
| 14 |
+
"learning_rate": 0.0001,
|
| 15 |
+
"loss": 1.469,
|
| 16 |
+
"step": 1
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.017777777777777778,
|
| 20 |
+
"grad_norm": 2.022883653640747,
|
| 21 |
+
"learning_rate": 9.698463103929542e-05,
|
| 22 |
+
"loss": 2.9751,
|
| 23 |
+
"step": 2
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.02666666666666667,
|
| 27 |
+
"grad_norm": 1.2307357788085938,
|
| 28 |
+
"learning_rate": 8.83022221559489e-05,
|
| 29 |
+
"loss": 1.8521,
|
| 30 |
+
"step": 3
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.035555555555555556,
|
| 34 |
+
"grad_norm": 2.503842830657959,
|
| 35 |
+
"learning_rate": 7.500000000000001e-05,
|
| 36 |
+
"loss": 2.5627,
|
| 37 |
+
"step": 4
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 0.035555555555555556,
|
| 41 |
+
"eval_accuracy": 0.6939260670748238,
|
| 42 |
+
"eval_loss": 1.9984581470489502,
|
| 43 |
+
"eval_runtime": 20.9951,
|
| 44 |
+
"eval_samples_per_second": 4.763,
|
| 45 |
+
"eval_steps_per_second": 4.763,
|
| 46 |
+
"step": 4
|
| 47 |
+
},
|
| 48 |
+
{
|
| 49 |
+
"epoch": 0.044444444444444446,
|
| 50 |
+
"grad_norm": 1.6151976585388184,
|
| 51 |
+
"learning_rate": 5.868240888334653e-05,
|
| 52 |
+
"loss": 1.7733,
|
| 53 |
+
"step": 5
|
| 54 |
+
},
|
| 55 |
+
{
|
| 56 |
+
"epoch": 0.05333333333333334,
|
| 57 |
+
"grad_norm": 1.3629400730133057,
|
| 58 |
+
"learning_rate": 4.131759111665349e-05,
|
| 59 |
+
"loss": 1.5353,
|
| 60 |
+
"step": 6
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"epoch": 0.06222222222222222,
|
| 64 |
+
"grad_norm": 2.5036630630493164,
|
| 65 |
+
"learning_rate": 2.500000000000001e-05,
|
| 66 |
+
"loss": 1.3856,
|
| 67 |
+
"step": 7
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"epoch": 0.07111111111111111,
|
| 71 |
+
"grad_norm": 2.502861499786377,
|
| 72 |
+
"learning_rate": 1.1697777844051105e-05,
|
| 73 |
+
"loss": 2.2846,
|
| 74 |
+
"step": 8
|
| 75 |
+
},
|
| 76 |
+
{
|
| 77 |
+
"epoch": 0.07111111111111111,
|
| 78 |
+
"eval_accuracy": 0.6973038730142216,
|
| 79 |
+
"eval_loss": 1.685868740081787,
|
| 80 |
+
"eval_runtime": 21.1016,
|
| 81 |
+
"eval_samples_per_second": 4.739,
|
| 82 |
+
"eval_steps_per_second": 4.739,
|
| 83 |
+
"step": 8
|
| 84 |
+
},
|
| 85 |
+
{
|
| 86 |
+
"epoch": 0.08,
|
| 87 |
+
"grad_norm": 2.4686763286590576,
|
| 88 |
+
"learning_rate": 3.0153689607045845e-06,
|
| 89 |
+
"loss": 1.6419,
|
| 90 |
+
"step": 9
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"epoch": 0.08888888888888889,
|
| 94 |
+
"grad_norm": 1.3143010139465332,
|
| 95 |
+
"learning_rate": 0.0,
|
| 96 |
+
"loss": 1.367,
|
| 97 |
+
"step": 10
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"epoch": 0.08888888888888889,
|
| 101 |
+
"step": 10,
|
| 102 |
+
"total_flos": 591688209530880.0,
|
| 103 |
+
"train_loss": 1.8846651792526246,
|
| 104 |
+
"train_runtime": 97.4531,
|
| 105 |
+
"train_samples_per_second": 0.821,
|
| 106 |
+
"train_steps_per_second": 0.103
|
| 107 |
+
}
|
| 108 |
+
],
|
| 109 |
+
"logging_steps": 1,
|
| 110 |
+
"max_steps": 10,
|
| 111 |
+
"num_input_tokens_seen": 0,
|
| 112 |
+
"num_train_epochs": 1,
|
| 113 |
+
"save_steps": 4,
|
| 114 |
+
"stateful_callbacks": {
|
| 115 |
+
"TrainerControl": {
|
| 116 |
+
"args": {
|
| 117 |
+
"should_epoch_stop": false,
|
| 118 |
+
"should_evaluate": false,
|
| 119 |
+
"should_log": false,
|
| 120 |
+
"should_save": true,
|
| 121 |
+
"should_training_stop": true
|
| 122 |
+
},
|
| 123 |
+
"attributes": {}
|
| 124 |
+
}
|
| 125 |
+
},
|
| 126 |
+
"total_flos": 591688209530880.0,
|
| 127 |
+
"train_batch_size": 1,
|
| 128 |
+
"trial_name": null,
|
| 129 |
+
"trial_params": null
|
| 130 |
+
}
|
training_eval_accuracy.png
ADDED
|
training_eval_loss.png
ADDED

|
training_loss.png
ADDED
|