
Tom Aarsen
commited on
Commit
·
64f74e2
1
Parent(s):
a4605b3
Add evaluation results to repository
Browse files- README.md +25 -1
- img/similarity_matryoshka.png +0 -0
- img/similarity_mteb_eval.png +0 -0
- img/similarity_speed.png +0 -0
README.md
CHANGED
|
@@ -131,7 +131,9 @@ co2_eq_emissions:
|
|
| 131 |
|
| 132 |
This is a [sentence-transformers](https://www.SBERT.net) model trained on the [wikititles](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-wikititles), [tatoeba](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-tatoeba), [talks](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [europarl](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-europarl), [global_voices](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-global-voices), [muse](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-muse), [wikimatrix](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-wikimatrix), [opensubtitles](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-opensubtitles), [stackexchange](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates), [quora](https://huggingface.co/datasets/sentence-transformers/quora-duplicates), [wikianswers_duplicates](https://huggingface.co/datasets/sentence-transformers/wikianswers-duplicates), [all_nli](https://huggingface.co/datasets/sentence-transformers/all-nli), [simple_wiki](https://huggingface.co/datasets/sentence-transformers/simple-wiki), [altlex](https://huggingface.co/datasets/sentence-transformers/altlex), [flickr30k_captions](https://huggingface.co/datasets/sentence-transformers/flickr30k-captions), [coco_captions](https://huggingface.co/datasets/sentence-transformers/coco-captions), [nli_for_simcse](https://huggingface.co/datasets/sentence-transformers/nli-for-simcse) and [negation](https://huggingface.co/datasets/jinaai/negation-dataset) datasets. It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, paraphrase mining, text classification, clustering, and more.
|
| 133 |
|
| 134 |
-
This model was trained with a [Matryoshka loss](https://huggingface.co/blog/matryoshka), allowing you to truncate the embeddings for faster
|
|
|
|
|
|
|
| 135 |
|
| 136 |
## Model Details
|
| 137 |
|
|
@@ -250,6 +252,28 @@ You can finetune this model on your own dataset.
|
|
| 250 |
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
|
| 251 |
-->
|
| 252 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 253 |
<!--
|
| 254 |
## Bias, Risks and Limitations
|
| 255 |
|
|
|
|
| 131 |
|
| 132 |
This is a [sentence-transformers](https://www.SBERT.net) model trained on the [wikititles](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-wikititles), [tatoeba](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-tatoeba), [talks](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [europarl](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-europarl), [global_voices](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-global-voices), [muse](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-muse), [wikimatrix](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-wikimatrix), [opensubtitles](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-opensubtitles), [stackexchange](https://huggingface.co/datasets/sentence-transformers/stackexchange-duplicates), [quora](https://huggingface.co/datasets/sentence-transformers/quora-duplicates), [wikianswers_duplicates](https://huggingface.co/datasets/sentence-transformers/wikianswers-duplicates), [all_nli](https://huggingface.co/datasets/sentence-transformers/all-nli), [simple_wiki](https://huggingface.co/datasets/sentence-transformers/simple-wiki), [altlex](https://huggingface.co/datasets/sentence-transformers/altlex), [flickr30k_captions](https://huggingface.co/datasets/sentence-transformers/flickr30k-captions), [coco_captions](https://huggingface.co/datasets/sentence-transformers/coco-captions), [nli_for_simcse](https://huggingface.co/datasets/sentence-transformers/nli-for-simcse) and [negation](https://huggingface.co/datasets/jinaai/negation-dataset) datasets. It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, paraphrase mining, text classification, clustering, and more.
|
| 133 |
|
| 134 |
+
This model was trained with a [Matryoshka loss](https://huggingface.co/blog/matryoshka), allowing you to truncate the embeddings for faster retrieval at minimal performance costs.
|
| 135 |
+
|
| 136 |
+
See [Evaluations](#evaluation) for details on performance on NanoBEIR, embedding speed, and Matryoshka dimensionality truncation.
|
| 137 |
|
| 138 |
## Model Details
|
| 139 |
|
|
|
|
| 252 |
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
|
| 253 |
-->
|
| 254 |
|
| 255 |
+
## Evaluation
|
| 256 |
+
|
| 257 |
+
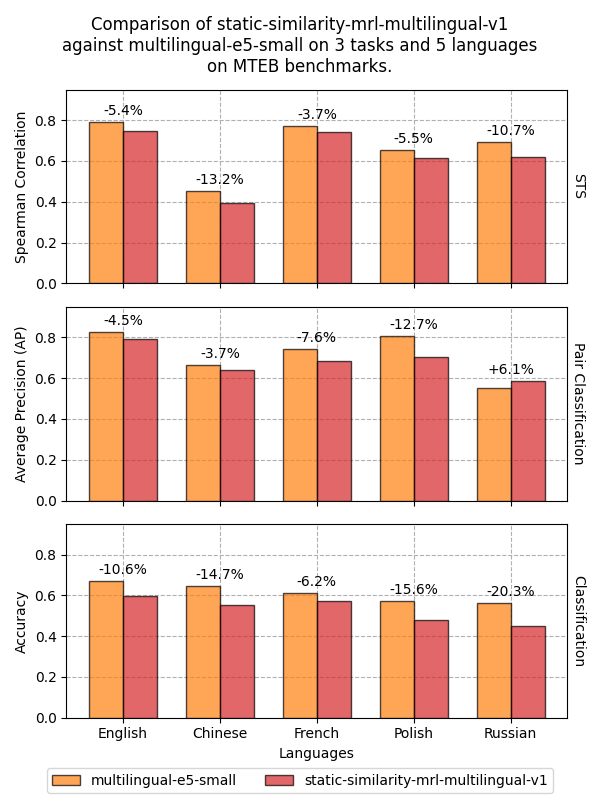
We've evaluated the model on 5 languages which have a lot of benchmarks across various tasks on [MTEB](https://huggingface.co/spaces/mteb/leaderboard).
|
| 258 |
+
|
| 259 |
+
We want to reiterate that this model is not intended for retrieval use cases. Instead, we evaluate on Semantic Textual Similarity (STS), Classification, and Pair Classification. We compare against the excellent and small [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) model.
|
| 260 |
+
|
| 261 |
+

|
| 262 |
+
|
| 263 |
+
Across all measured languages, [static-similarity-mrl-multilingual-v1](https://huggingface.co/sentence-transformers/static-similarity-mrl-multilingual-v1) reaches an average **92.3%** for STS, **95.52%** for Pair Classification, and **86.52%** for Classification relative to [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small).
|
| 264 |
+
|
| 265 |
+

|
| 266 |
+
|
| 267 |
+
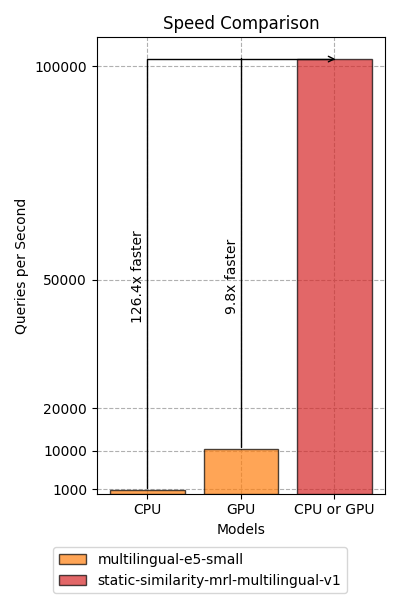
To make up for this performance reduction, [static-similarity-mrl-multilingual-v1](https://huggingface.co/sentence-transformers/static-similarity-mrl-multilingual-v1) is approximately ~125x faster on CPU and ~10x faster on GPU devices than [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small). Due to the super-linear nature of attention models, versus the linear nature of static embedding models, the speedup will only grow larger as the number of tokens to encode increases.
|
| 268 |
+
|
| 269 |
+
#### Matryoshka Evaluation
|
| 270 |
+
|
| 271 |
+
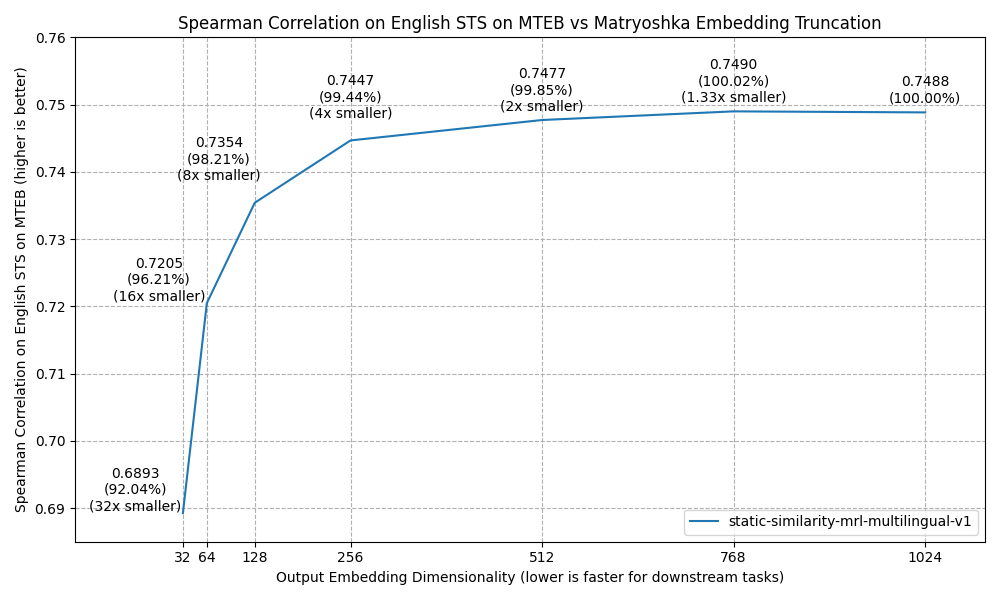
Lastly, we experimented with the impacts on English STS on MTEB performance when we did Matryoshka-style dimensionality reduction by truncating the output embeddings to a lower dimensionality.
|
| 272 |
+
|
| 273 |
+

|
| 274 |
+
|
| 275 |
+
As you can see, you can easily reduce the dimensionality by 2x or 4x with minor (0.15% or 0.56%) performance hits. If the speed of your downstream task or your storage costs are a bottleneck, this should allow you to alleviate some of those concerns.
|
| 276 |
+
|
| 277 |
<!--
|
| 278 |
## Bias, Risks and Limitations
|
| 279 |
|
img/similarity_matryoshka.png
ADDED
|
img/similarity_mteb_eval.png
ADDED
|
img/similarity_speed.png
ADDED
|