
DeepSeek-V3
Collection
2 items
•
Updated
•
81

We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks.
Architecture: Innovative Load Balancing Strategy and Training Objective
Pre-Training: Towards Ultimate Training Efficiency
Post-Training: Knowledge Distillation from DeepSeek-R1
| Model | #Total Params | #Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-V3-Base | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-V3 | 671B | 37B | 128K | 🤗 HuggingFace |
NOTE: The total size of DeepSeek-V3 models on HuggingFace is 685B, which includes 671B of the Main Model weights and 14B of the Multi-Token Prediction (MTP) Module weights.
To ensure optimal performance and flexibility, we have partnered with open-source communities and hardware vendors to provide multiple ways to run the model locally. For step-by-step guidance, check out Section 6: How_to Run_Locally.
For developers looking to dive deeper, we recommend exploring README_WEIGHTS.md for details on the Main Model weights and the Multi-Token Prediction (MTP) Modules. Please note that MTP support is currently under active development within the community, and we welcome your contributions and feedback.
| Benchmark (Metric) | # Shots | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 | |
|---|---|---|---|---|---|---|
| Architecture | - | MoE | Dense | Dense | MoE | |
| # Activated Params | - | 21B | 72B | 405B | 37B | |
| # Total Params | - | 236B | 72B | 405B | 671B | |
| English | Pile-test (BPB) | - | 0.606 | 0.638 | 0.542 | 0.548 |
| BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | 87.5 | |
| MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | 87.1 | |
| MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | 86.2 | |
| MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | 64.4 | |
| DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | 89.0 | |
| ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | 98.9 | |
| ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | 95.3 | 95.3 | |
| HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | 89.2 | 88.9 | |
| PIQA (Acc.) | 0-shot | 83.9 | 82.6 | 85.9 | 84.7 | |
| WinoGrande (Acc.) | 5-shot | 86.3 | 82.3 | 85.2 | 84.9 | |
| RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | 74.2 | 67.1 | |
| RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | 56.8 | 51.3 | |
| TriviaQA (EM) | 5-shot | 80.0 | 71.9 | 82.7 | 82.9 | |
| NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | 41.5 | 40.0 | |
| AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | 79.6 | |
| Code | HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | 65.2 |
| MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | 75.4 | |
| LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | 19.4 | |
| CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | 67.3 | |
| CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | 69.8 | |
| Math | GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | 89.3 |
| MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | 61.6 | |
| MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | 79.8 | |
| CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | 90.7 | |
| Chinese | CLUEWSC (EM) | 5-shot | 82.0 | 82.5 | 83.0 | 82.7 |
| C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | 90.1 | |
| CMMLU (Acc.) | 5-shot | 84.0 | 89.5 | 73.7 | 88.8 | |
| CMRC (EM) | 1-shot | 77.4 | 75.8 | 76.0 | 76.3 | |
| C3 (Acc.) | 0-shot | 77.4 | 76.7 | 79.7 | 78.6 | |
| CCPM (Acc.) | 0-shot | 93.0 | 88.5 | 78.6 | 92.0 | |
| Multilingual | MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | 79.4 |
Note: Best results are shown in bold. Scores with a gap not exceeding 0.3 are considered to be at the same level. DeepSeek-V3 achieves the best performance on most benchmarks, especially on math and code tasks. For more evaluation details, please check our paper.
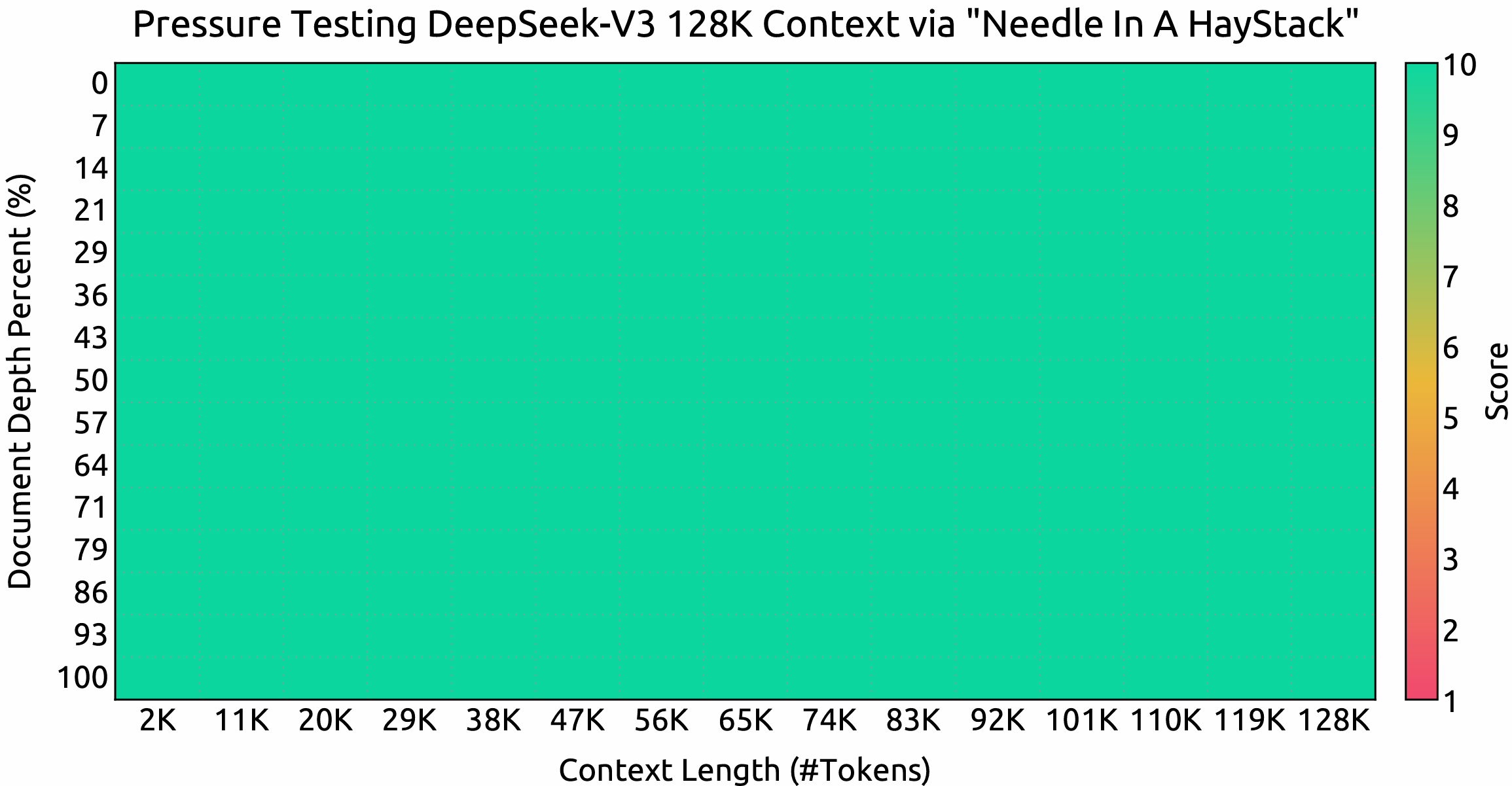
Evaluation results on the Needle In A Haystack (NIAH) tests. DeepSeek-V3 performs well across all context window lengths up to 128K.
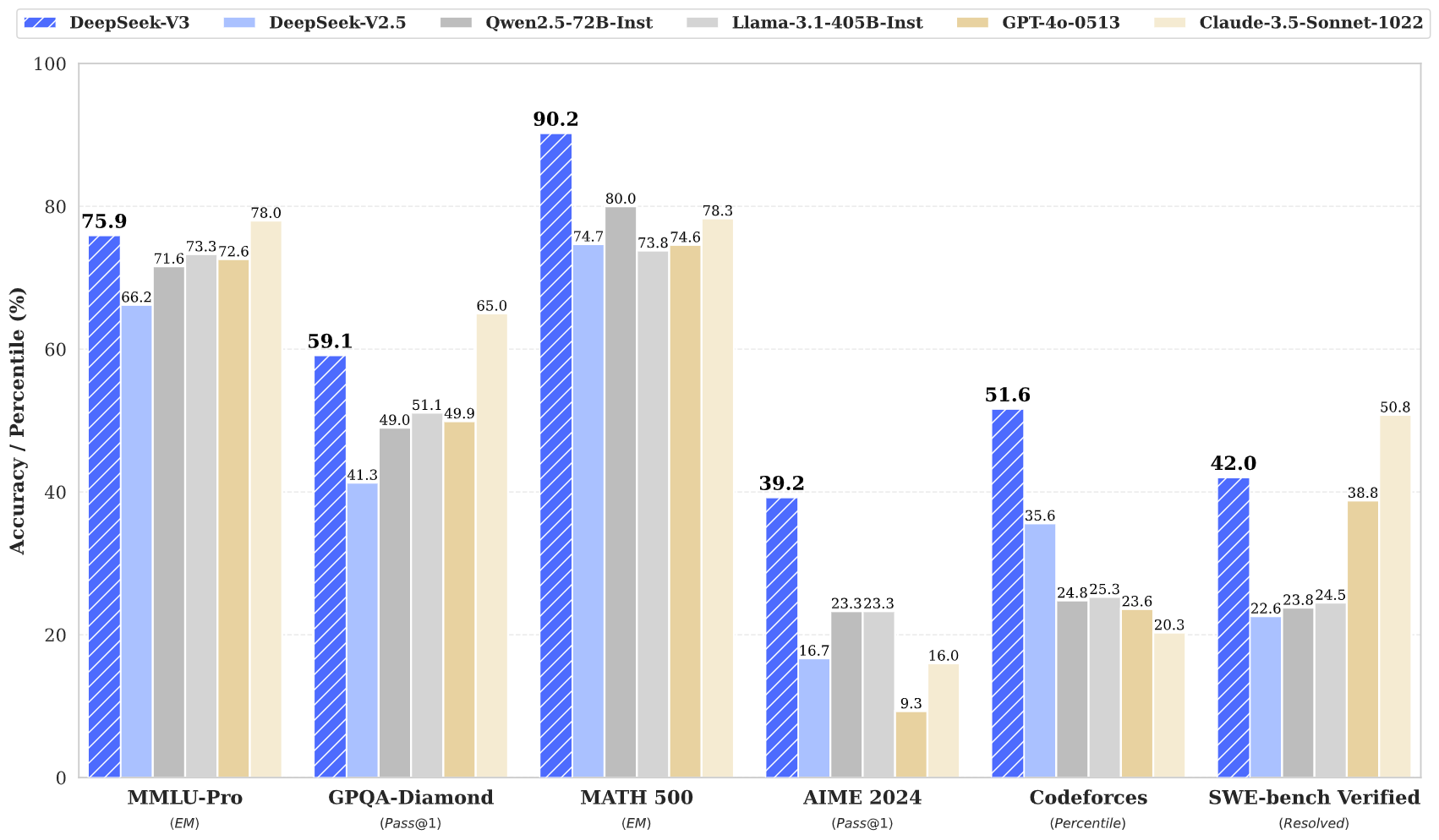
| Benchmark (Metric) | DeepSeek V2-0506 | DeepSeek V2.5-0905 | Qwen2.5 72B-Inst. | Llama3.1 405B-Inst. | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | |
|---|---|---|---|---|---|---|---|---|
| Architecture | MoE | MoE | Dense | Dense | - | - | MoE | |
| # Activated Params | 21B | 21B | 72B | 405B | - | - | 37B | |
| # Total Params | 236B | 236B | 72B | 405B | - | - | 671B | |
| English | MMLU (EM) | 78.2 | 80.6 | 85.3 | 88.6 | 88.3 | 87.2 | 88.5 |
| MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | 88.9 | 88.0 | 89.1 | |
| MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | 78.0 | 72.6 | 75.9 | |
| DROP (3-shot F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | 91.6 | |
| IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | 86.5 | 84.3 | 86.1 | |
| GPQA-Diamond (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | 65.0 | 49.9 | 59.1 | |
| SimpleQA (Correct) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | 38.2 | 24.9 | |
| FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | 80.5 | 73.3 | |
| LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | 48.7 | |
| Code | HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | 82.6 |
| LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | 40.5 | |
| LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | 37.6 | |
| Codeforces (Percentile) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | 51.6 | |
| SWE Verified (Resolved) | - | 22.6 | 23.8 | 24.5 | 50.8 | 38.8 | 42.0 | |
| Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | 84.2 | 72.9 | 79.7 | |
| Aider-Polyglot (Acc.) | - | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | 49.6 | |
| Math | AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | 39.2 |
| MATH-500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | 90.2 | |
| CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | 43.2 | |
| Chinese | CLUEWSC (EM) | 89.9 | 90.4 | 91.4 | 84.7 | 85.4 | 87.9 | 90.9 |
| C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | 86.5 | |
| C-SimpleQA (Correct) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | 64.8 |
Note: All models are evaluated in a configuration that limits the output length to 8K. Benchmarks containing fewer than 1000 samples are tested multiple times using varying temperature settings to derive robust final results. DeepSeek-V3 stands as the best-performing open-source model, and also exhibits competitive performance against frontier closed-source models.
| Model | Arena-Hard | AlpacaEval 2.0 |
|---|---|---|
| DeepSeek-V2.5-0905 | 76.2 | 50.5 |
| Qwen2.5-72B-Instruct | 81.2 | 49.1 |
| LLaMA-3.1 405B | 69.3 | 40.5 |
| GPT-4o-0513 | 80.4 | 51.1 |
| Claude-Sonnet-3.5-1022 | 85.2 | 52.0 |
| DeepSeek-V3 | 85.5 | 70.0 |
Note: English open-ended conversation evaluations. For AlpacaEval 2.0, we use the length-controlled win rate as the metric.
You can chat with DeepSeek-V3 on DeepSeek's official website: chat.deepseek.com
We also provide OpenAI-Compatible API at DeepSeek Platform: platform.deepseek.com
DeepSeek-V3 can be deployed locally using the following hardware and open-source community software:
Since FP8 training is natively adopted in our framework, we only provide FP8 weights. If you require BF16 weights for experimentation, you can use the provided conversion script to perform the transformation.
Here is an example of converting FP8 weights to BF16:
cd inference
python fp8_cast_bf16.py --input-fp8-hf-path /path/to/fp8_weights --output-bf16-hf-path /path/to/bf16_weights
NOTE: Huggingface's Transformers has not been directly supported yet.
First, clone our DeepSeek-V3 GitHub repository:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git
Navigate to the inference folder and install dependencies listed in requirements.txt.
cd DeepSeek-V3/inference
pip install -r requirements.txt
Download the model weights from HuggingFace, and put them into /path/to/DeepSeek-V3 folder.
Convert HuggingFace model weights to a specific format:
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16
Then you can chat with DeepSeek-V3:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --interactive --temperature 0.7 --max-new-tokens 200
Or batch inference on a given file:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE
SGLang currently supports MLA optimizations, FP8 (W8A8), FP8 KV Cache, and Torch Compile, delivering state-of-the-art latency and throughput performance among open-source frameworks.
Notably, SGLang v0.4.1 fully supports running DeepSeek-V3 on both NVIDIA and AMD GPUs, making it a highly versatile and robust solution.
Here are the launch instructions from the SGLang team: https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
LMDeploy, a flexible and high-performance inference and serving framework tailored for large language models, now supports DeepSeek-V3. It offers both offline pipeline processing and online deployment capabilities, seamlessly integrating with PyTorch-based workflows.
For comprehensive step-by-step instructions on running DeepSeek-V3 with LMDeploy, please refer to here: https://github.com/InternLM/lmdeploy/issues/2960
TensorRT-LLM now supports the DeepSeek-V3 model, offering precision options such as BF16 and INT4/INT8 weight-only. Support for FP8 is currently in progress and will be released soon. You can access the custom branch of TRTLLM specifically for DeepSeek-V3 support through the following link to experience the new features directly: https://github.com/NVIDIA/TensorRT-LLM/tree/deepseek/examples/deepseek_v3.
vLLM v0.6.6 supports DeepSeek-V3 inference for FP8 and BF16 modes on both NVIDIA and AMD GPUs. Aside from standard techniques, vLLM offers pipeline parallelism allowing you to run this model on multiple machines connected by networks. For detailed guidance, please refer to the vLLM instructions. Please feel free to follow the enhancement plan as well.
In collaboration with the AMD team, we have achieved Day-One support for AMD GPUs using SGLang, with full compatibility for both FP8 and BF16 precision. For detailed guidance, please refer to the SGLang instructions.
The MindIE framework from the Huawei Ascend community has successfully adapted the BF16 version of DeepSeek-V3. For step-by-step guidance on Ascend NPUs, please follow the instructions here.
This code repository is licensed under the MIT License. The use of DeepSeek-V3 Base/Chat models is subject to the Model License. DeepSeek-V3 series (including Base and Chat) supports commercial use.
@misc{deepseekai2024deepseekv3technicalreport,
title={DeepSeek-V3 Technical Report},
author={DeepSeek-AI and Aixin Liu and Bei Feng and Bing Xue and Bingxuan Wang and Bochao Wu and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenyu Zhang and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fucong Dai and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and H. Zhang and Han Bao and Hanwei Xu and Haocheng Wang and Haowei Zhang and Honghui Ding and Huajian Xin and Huazuo Gao and Hui Li and Hui Qu and J. L. Cai and Jian Liang and Jianzhong Guo and Jiaqi Ni and Jiashi Li and Jiawei Wang and Jin Chen and Jingchang Chen and Jingyang Yuan and Junjie Qiu and Junlong Li and Junxiao Song and Kai Dong and Kai Hu and Kaige Gao and Kang Guan and Kexin Huang and Kuai Yu and Lean Wang and Lecong Zhang and Lei Xu and Leyi Xia and Liang Zhao and Litong Wang and Liyue Zhang and Meng Li and Miaojun Wang and Mingchuan Zhang and Minghua Zhang and Minghui Tang and Mingming Li and Ning Tian and Panpan Huang and Peiyi Wang and Peng Zhang and Qiancheng Wang and Qihao Zhu and Qinyu Chen and Qiushi Du and R. J. Chen and R. L. Jin and Ruiqi Ge and Ruisong Zhang and Ruizhe Pan and Runji Wang and Runxin Xu and Ruoyu Zhang and Ruyi Chen and S. S. Li and Shanghao Lu and Shangyan Zhou and Shanhuang Chen and Shaoqing Wu and Shengfeng Ye and Shengfeng Ye and Shirong Ma and Shiyu Wang and Shuang Zhou and Shuiping Yu and Shunfeng Zhou and Shuting Pan and T. Wang and Tao Yun and Tian Pei and Tianyu Sun and W. L. Xiao and Wangding Zeng and Wanjia Zhao and Wei An and Wen Liu and Wenfeng Liang and Wenjun Gao and Wenqin Yu and Wentao Zhang and X. Q. Li and Xiangyue Jin and Xianzu Wang and Xiao Bi and Xiaodong Liu and Xiaohan Wang and Xiaojin Shen and Xiaokang Chen and Xiaokang Zhang and Xiaosha Chen and Xiaotao Nie and Xiaowen Sun and Xiaoxiang Wang and Xin Cheng and Xin Liu and Xin Xie and Xingchao Liu and Xingkai Yu and Xinnan Song and Xinxia Shan and Xinyi Zhou and Xinyu Yang and Xinyuan Li and Xuecheng Su and Xuheng Lin and Y. K. Li and Y. Q. Wang and Y. X. Wei and Y. X. Zhu and Yang Zhang and Yanhong Xu and Yanhong Xu and Yanping Huang and Yao Li and Yao Zhao and Yaofeng Sun and Yaohui Li and Yaohui Wang and Yi Yu and Yi Zheng and Yichao Zhang and Yifan Shi and Yiliang Xiong and Ying He and Ying Tang and Yishi Piao and Yisong Wang and Yixuan Tan and Yiyang Ma and Yiyuan Liu and Yongqiang Guo and Yu Wu and Yuan Ou and Yuchen Zhu and Yuduan Wang and Yue Gong and Yuheng Zou and Yujia He and Yukun Zha and Yunfan Xiong and Yunxian Ma and Yuting Yan and Yuxiang Luo and Yuxiang You and Yuxuan Liu and Yuyang Zhou and Z. F. Wu and Z. Z. Ren and Zehui Ren and Zhangli Sha and Zhe Fu and Zhean Xu and Zhen Huang and Zhen Zhang and Zhenda Xie and Zhengyan Zhang and Zhewen Hao and Zhibin Gou and Zhicheng Ma and Zhigang Yan and Zhihong Shao and Zhipeng Xu and Zhiyu Wu and Zhongyu Zhang and Zhuoshu Li and Zihui Gu and Zijia Zhu and Zijun Liu and Zilin Li and Ziwei Xie and Ziyang Song and Ziyi Gao and Zizheng Pan},
year={2024},
eprint={2412.19437},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.19437},
}
If you have any questions, please raise an issue or contact us at [email protected].